그중, 흔히 말하는 시간 복잡도 O(n²) 정렬들은 구현도 간단하여 자주 사용하는 편인데, 정작 각 정렬에 대한 차이를 명확하게 답변하지 못할때가 종종 있어서 복습 겸 정리를 좀 할까 싶다.
1. 해당 문서의 예시 코드는 C/C++ 기반으로 작성되었습니다.
2. 모든 설명은 오름차순을 기준으로 합니다.
삽입 정렬
삽입정렬은 "맨 처음부터 진행하면서 내 위치일 것 같은곳으로 삽입" 하는 정렬이다.
예를들어, [5 3 2 1 4] 의 순서로 자료가 있다고 하면
시작 - [5 3 2 1 4]
1회차 - [5 3 2 1 4] --> [3 5 2 1 4]
2회차 - [3 5 2 1 4] --> [2 3 5 1 4]
3회차 - [2 3 5 1 4] --> [1 2 3 5 4]
4회차 - [1 2 3 5 4] --> [1 2 3 4 5]
종료 - [1 2 3 4 5]
의 방식으로 정렬이 이루어진다.
삽입 정렬의 특징이자 문제점이, "삽입" 방식으로 이루어지다보니 중간에 데이터를 삽입하면 뒤로 밀어버려야 한다는 특징이 있는데..
코드를 보면서 설명하도록 하겠다.
void Insertion_Sort(int *data, int n) //data = int 동적배열, n = 배열 길이
{
int i, j;
int temp; //임시 기억용 변수
for (i = 1 ; i < n ; i++) //2번째 원소부터 검사하므로 index가 1부터 시작함.
{
j = i;
temp = data[i];
while (--j >= 0 && data[j] > temp) //검사중인 원소부터
{ //0번 인덱스 원소까지
data[j+1] = data[j]; //한칸씩 뒤로 당김
} //* while문 최초 실행때 [j+1] 원소는 temp에 들어간 원소와 같다.
data[j+1] = temp; // j = i = 1일때, j + 1은 0이 될 수 있다.
}
}
흐름은 다음과 같다.
시작을 i 번 원소부터 했을때
1. [i - 1] 원소가 [i] 보다 클때 = i 원소의 값을 [i - 1]로 바꾼다.
2. [i - 1] 원소가 [i] 보다 작을때 = 값을 바꾸지 않고 종료한다.
3. while 루프 종료시 = 최종 위치에 임시값을 삽입한다. (1, 2번을 수행하면서 생긴 "중복 값" (=빈 자리) 에 삽입)
여기 나오는 모든 정렬들이 그렇겠지만, 삽입정렬도 N번째 값 정렬 시 N-1만큼의 순회를 돌아야 하므로, 시간 복잡도는 O (N(N-1)) = O(n² - n) = O(n²) 로 수렴한다.
구현이 간단하고, 나름 빠른 편 (선택 정렬과 버블정렬은 순수하게 O(n²) 의 시간 복잡도를 가진다) 이나, 배열이 길어질수록 효율이 떨어진다는 단점이 존재한다.
이미 정렬이 되어있는 경우에는 비교를 제외한 추가적인 연산이 필요 없으므로 최선의 케이스가 나오며, 이때 시간 복잡도는 O(n) 이 나온다.
선택 정렬
선택 정렬은 "리스트의 최소값부터 정렬하는" 알고리즘이다.
삽입정렬과 헷깔릴 수 있는데, 선택정렬은 N번째 자료를 정렬시에 N-1번까지는 이미 정렬이 완전히 끝난 상태라는것이 가장 큰 차이. (위에도 언급했지만 삽입정렬은 N번째 자료 정렬시 정렬이 끝난다는 보장을 할 수 없다.)
선택 정렬은 다음과 같이 작동한다.
시작 - [5 3 2 1 4]
1회차 - [532 1 4] --> [1 3 2 5 4]
2회차 - [1 3 2 5 4] --> [1 23 5 4]
3회차 - [1 2 3 5 4] --> [1 2 3 5 4] // 이미 순서가 맞으므로 추가 정렬 X
4회차 - [1 2 3 54] --> [1 2 345]
종료 - [1 2 3 4 5]
선택 정렬은 N번째 자료 정렬시 그 앞까지 (N-1까지)는 정렬이 완료되었다는 보장을 할 수 있는데, 현재 값이 "어느 위치인지" 알기 위해서 결국 모든 자료를 검사해야한다는 불상사가 발생한다.
이게 무슨소리냐면... 시간 복잡도가 어떤 상황에서든 O(n²) 라는 것이다.
삽입 정렬이나 버블정렬의 경우에는, 비교하는 대상과 본인이 정렬이 되어있다면 추가적인 연산을 하지 않는데 선택정렬은 그런거 모르겠고 이미 끝난 정렬도 함수 안에서 정렬을 수행한다는 뜻이다.
선택정렬은 "다음 최소값"이 어떤 값인지 알아야 하는 문제가 있어, 삽입정렬이나 버블정렬보다는 로직이 조금 복잡한 편이다.
void SelectionSort(int *data, int n)
{
int i, j, indexMin, temp; //최소값 인덱스와 임시값 변수 2종이 추가로 필요함.
for (i = 0 ; i < n-1 ; i++)
{
indexMin = i;
for (j = i+1 ; j < n ; j++)
{
//해당 for문은 정렬되지 않은 구역에서 "최소값"을 찾는 로직이다.
if (data[j] < data[indexMin])
{
indexMin = j;
}
}
temp = data[indexMin]; //찾아낸 최소값을 temp에 저장.
data [indexMin] = data[i]; //위치 교환
data[i] = temp; //temp값을 위치에 저장
}
}
흐름은 다음과 같다.
시작을 i 번 원소부터 했을때
1. i번 부터 N번까지 데이터 중 최소값을 찾는다.
2. 최소값이 발견되면 해당 값의 인덱스를 기록한다.
3. 최소값을 임시 변수에 저장한다.
4. i번 값과 최소값이 위치한 인덱스의 값을 교체한다.
5. i번 값에 임시 변수에 저장된 값을 집어넣는다.
해당 과정은 값이 이미 정렬이 되어있던, 아니던 상관없이 작동한다. 그러니까 시간 복잡도가 그모양이지
C++에 들어오면서, "기존의 로우 포인터(=Raw Pointer) 에서 발생할 수 있는 문제들을 해결하기 위한 포인터"를 만들겠다는 명목하에 스마트 포인터라는 포인터가 추가되었다.
Raw Pointer 를 쓰면 생기는 문제점은 크게
1. 메모리를 사용했는데 해제 안한 경우 = 메모리가 낭비되는 현상 (=메모리 누수 / Memory Leak) 가 발생
2. 메모리를 사용하던 중에 해제한 경우, 해제한 메모리를 접근하는 경우
= 잘못된 참조 (Dangling Pointer) 발생으로 크래시 위험
둘다 문제가 많은 상황인데,
해제를 안한 경우가 "언제 터질지 모르는 시한폭탄" 이라면, 해제된 메모리 접근은 "지뢰" 라고 볼 수 있다.
둘다 터지면 머리아픈건 매한가지지만
주요 이론은, "객체는 (특별한 문제가 없는 한) 사라질때 소멸자가 반드시 호출되며, 이때 자원 해제를 하게 되면 자원 해제와 관련된 문제가 해결되지 않을까?" 라는 마인드에 입각하여(*1) 포인터를 포인터 객체로 만들어서, 해당 객체가 소멸시 데이터까지 같이 delete 하도록 하여 각종 포인터 예외를 대응하고자 한것이다.
다양한 스마트 포인터가 있고, 각자 다양한 목적을 위해 사용하는데 각각에 대한 정보를 정리를 한번 해야할것 같아 스스로 이해한 부분에 대해 정리를 해보고자 한다.
물론, 이미 Duplicated 된 Auto_Ptr은 생략한다...
해당 문서에는 각 스마트포인터의 사용법보단, 구조 및 원리에 대해 주로 설명합니다.
사용법이 필요하다면 적당히 찾아보시거나 직접 연구해보시는것을 추천합니다.
1) 해당 내용과 관련된 디자인 패턴이 RAII 라고 불리는 객체를 통한 자원 획득 디자인 패턴임. RAII : Resource Acquisition Is Initialization
Unique_Ptr
unique_ptr은 특정 객체에 대한 유일한 소유권을 가지는 스마트 포인터이다.
대체로, 유일한 소유권을 가지는 경우에 대해 "이걸 왜 쓰냐" 라는 의문을 가질때가 종종 있는데
다음과 같은 경우에 주로 문제가 발생한다.
Data* data1 = new Data();
Data* data2 = data1;
delete data1;// = data1 에 연결된 객체 소멸 (=new data() 로 선언한 객체)
delete data2;// = data2 에 연결된 객체 소멸 (=data1 (= new data()로 선언한 객체)
간단히 설명하면, data1 포인터에 새로운 data 객체를 만들어줬고, 이를 data2에서도 참조할 수 있도록 해놨는데,
수행 이후 data1 포인터를 통해 객체를 소멸시켰으나, data2에서도 연결된 객체를 소멸시키려고 하는 상황이다.
이때, 이미 삭제된 객체를 삭제하려고 시도해서 메모리 오류가 발생하며 Crash가 발생하게 된다.
"그럼 객체 소멸을 한가지 포인터만 하게 하면 되지 않나요?" 란 의문에서 나온것이 바로 unique_ptr 되시겠다.
특정 객체의 소유권을 지정하여 해당 포인터에서만 객체 접근 및 소멸을 담당하게 하면, 다른 포인터가 임의로 객체를 파괴시키는 현상은 일어나지 않게 될것이다. 또한, 위에서 설명한 문제중 "포인터를 쓰고 해제 하지 않는 문제"를 RAII 패턴에 입각하여 대응을 한것이 unique_ptr이고, 이는 일반적인 포인터처럼 사용할 수 있으나 다음과 같은 특징을 가지고 있다.
1. 특정 객체 (= 특정 클래스로 이루어진 메모리 영역) 에 대해 유일한 소유권을 가진다.
2. 함수 스택에 포함된 객체로, 함수가 끝나면 소멸자가 호출되며 메모리를 자동으로 해제한다.
사실, 2번에 대해서는 이해하기가 쉬운데, 1번은 "그걸 어떻게 알 수 있는데?" 라는 의문이 생길 수 있다.
안그래도 궁금해서 좀 찾아보았는데, unique_ptr 구현부에 다음과 같은 항목이 있었다.
/** Takes ownership of a pointer.
*
* @param __p A pointer to an object of @c element_type
* @param __d A reference to a deleter.
*
* The deleter will be initialized with @p __d
*/
template<typename _Del = deleter_type,
typename = _Require<is_copy_constructible<_Del>>>
unique_ptr(pointer __p, const deleter_type& __d) noexcept
: _M_t(__p, __d) { }
/** Takes ownership of a pointer.
*
* @param __p A pointer to an object of @c element_type
* @param __d An rvalue reference to a (non-reference) deleter.
*
* The deleter will be initialized with @p std::move(__d)
*/
template<typename _Del = deleter_type,
typename = _Require<is_move_constructible<_Del>>>
unique_ptr(pointer __p,
__enable_if_t<!is_lvalue_reference<_Del>::value,
_Del&&> __d) noexcept
: _M_t(__p, std::move(__d))
{ }
위는 할당, 아래는 "이동" 연산
여기서 보면 _M_t_ 라는 변수가 보이는데, 이는 __uniq_ptr_data 라는 구조체 변수이고, 해당 변수는 내부에 "__unique_ptr_impl" 라는 변수를 가지고 있다.
즉, 일반적인 복사 생성자나 대입 연산자는 삭제되어있으니, 당연히 접근하면 오류가 발생하는것이다.
'std::unique_ptr<A,std::default_delete<_Ty>>::unique_ptr(const std::unique_ptr<_Ty,std::default_delete<_Ty>> &)': attempting to reference a deleted function
오류 메시지는 다음과 같이 나온다. 삭제된 함수 (= 여기서는 복사, 대입 연산자)에 접근하려고 했다는 뜻.
이와 같은 방법으로 unique_ptr 간의 소유권을 지정할 수 있게 되었으며 (정확히는 조금.... 눈가리고 아웅 같긴 하지만) RAII 패턴에 힘입어 안전한 해제까지 보장되게 된 것이다.
p.s -
주의사항 : 물론, 설명에 없는것에서 눈치챘을수도 있지만 소유권이 이전된 빈 포인터가 된 unique_ptr에 포인터 연산을 시도 시 댕글링 포인터 문제로 인해 런타임 오류가 발생한다.
Shared_Ptr
근데 내가 특정 객체를 여러번 써야하는 경우가 있다면?
사실 이런 경우가 굉장히 흔하다. (오히려 unique_ptr을 쓰는 경우는 되게 드물었던것으로 기억한다.)
그렇다면 요구사항은 다음과 같이 정리된다.
1. 나는 한개의 객체를 여러개의 포인터로 접근하고 싶다.
2. 하지만, 그러면서 스마트 포인터의 특징 (= 안전한 해제)를 보장받고 싶다.
이를 위해 만들어진것이 바로 shared_ptr 되시겠다.
shared_ptr은 같은 객체를 다수의 스마트 포인터가 가리킬 수 있고, 내부적으로 레퍼런스 카운팅을 통해 몇번 참조중인지를 알 수 있는 스마트 포인터다.
레퍼런스 카운터가 0이 되면, 자동으로 해제되는 형태의 스마트 포인터로 알려져있는데.....
그럼 그 레퍼런스 카운터는 어떻게 되는가... 하면
__shared_count라는 서브 클래스가 따로 있고, (해당 클래스 내부에는 "_Sp_counted_base" 라는 클래스가 있다) 해당 클래스에서 카운트를 실시하는 스타일이다.
해당 정보는 같은 포인터를 가리키는 shared_ptr 끼리 공유하며 해당 공유 정보를 Control Block이라고 부른다.
즉, 레퍼런스 카운트 정보를 동일한 Control Block이 소유하고, 이를 각각의 shared_ptr이 공유하면서 사용하면 굳이 각 포인터에서 각자 카운터를 조작할 필요가 없게 되는것...
물론, 이를 위해서는 최초의 shared_ptr에서 접근을 늘려가야 하며 (즉, 최초의 shared_ptr을 제외한 N번째 shared_ptr은 최초의 shared_ptr을 가리켜야 한다), 1개의 raw pointer에서 다수의 shared_ptr을 새로 선언하면 shared_ptr이 자랑하는 레퍼런스 카운트 기능이 딱히 의미가 없어진다.
즉, shared_ptr에 raw pointer (=주소값)이 전달되면, 해당 shared_ptr은 본인이 해당 주소값을 최초로 소유한것으로 인지하게 된다는 것이다.
우선, std::sort를 검색하면 std::__sort 라는 inner func가 나온다.
/**
* @brief Sort the elements of a sequence using a predicate for comparison.
* @ingroup sorting_algorithms
* @param __first An iterator.
* @param __last Another iterator.
* @param __comp A comparison functor.
* @return Nothing.
*
* Sorts the elements in the range @p [__first,__last) in ascending order,
* such that @p __comp(*(i+1),*i) is false for every iterator @e i in the
* range @p [__first,__last-1).
*
* The relative ordering of equivalent elements is not preserved, use
* @p stable_sort() if this is needed.
*/
template<typename _RandomAccessIterator, typename _Compare>
_GLIBCXX20_CONSTEXPR
inline void
sort(_RandomAccessIterator __first, _RandomAccessIterator __last,
_Compare __comp)
{
// concept requirements
__glibcxx_function_requires(_Mutable_RandomAccessIteratorConcept<
_RandomAccessIterator>)
__glibcxx_function_requires(_BinaryPredicateConcept<_Compare,
typename iterator_traits<_RandomAccessIterator>::value_type,
typename iterator_traits<_RandomAccessIterator>::value_type>)
__glibcxx_requires_valid_range(__first, __last);
__glibcxx_requires_irreflexive_pred(__first, __last, __comp);
std::__sort(__first, __last, __gnu_cxx::__ops::__iter_comp_iter(__comp));
}
// sort
template<typename _RandomAccessIterator, typename _Compare>
_GLIBCXX20_CONSTEXPR
inline void
__sort(_RandomAccessIterator __first, _RandomAccessIterator __last,
_Compare __comp)
{
if (__first != __last)
{
std::__introsort_loop(__first, __last,
std::__lg(__last - __first) * 2,
__comp);
std::__final_insertion_sort(__first, __last, __comp);
}
}
해당 함수에서는, 시작과 끝이 일치하지 않을때 introSort 재귀함수를 진행하고, 종료 시점에 삽입 정렬을 수행한다.
introsort_loop (Instro sort 재귀함수) 에서는, 미리 정해진 threadhold 상수값을 기준으로 정렬을 선택해서 사용한다.
/// This is a helper function for the sort routine.
template<typename _RandomAccessIterator, typename _Size, typename _Compare>
_GLIBCXX20_CONSTEXPR
void
__introsort_loop(_RandomAccessIterator __first,
_RandomAccessIterator __last,
_Size __depth_limit, _Compare __comp)
{
while (__last - __first > int(_S_threshold))
{
if (__depth_limit == 0)
{
std::__partial_sort(__first, __last, __last, __comp);
return;
}
--__depth_limit;
_RandomAccessIterator __cut =
std::__unguarded_partition_pivot(__first, __last, __comp);
std::__introsort_loop(__cut, __last, __depth_limit, __comp);
__last = __cut;
}
}
_S_threadhold 라는 상수가 문제의 상수인데, 파일을 조금 뒤져보니 "16" 이란 값으로 임의로 박혀있었다.
왜 하필 16인지에 대해서는.... 더 찾아봐야할거같긴 한데 일단은 16이라니까 16이라고 보자.
Introsort_loop 의 로직은,
1. 리스트의 길이가 16 초과 일때 로직을 수행하고
2. depth limit가 0이 아니라면 -> depth limit를 1 줄이고, 임의 pivot을 선택한 후 instroSort를 반복해서 선택한다.
3. 여기서, depth limit는 함수 시작 시 2⌈ log₂(length) ⌉ (log 연산값의 정수 올림) 의 값을 가지고 시작한다.(해당 연산을 N번 반복하므로 정렬의 평균 속도가 O(n log₂n) 이 나오는것..)
4. 연산을 반복하다, depth limit가 0이 되었고 (= 연산의 깊이가 2⌈ log₂(length) ⌉ 돌파시), 길이가 16이상일 시 힙 정렬을 수행한다.
간단히, '상수화 키워드' 로 알려져 있는 이 키워드는, 말 그대로 해당 키워드가 붙는 모든것을 상수화 (고정값 화) 시켜버린다.
여기서 알아두어야 할 것이, 모든 것이라는 점인데, 단순히 변수는 물론이고, 함수 삽입값(파라미터), 함수 리턴값, 심지어는 클래스/객체에도 사용이 가능하다.
근데 이게 어디 붙여도 다 상수화.... 되는건 맞는거 같은데, 좀 헷깔리는 감이 없잖아 있어서 정리를 좀 해보고자 한다.
일단 알아두어야 할 점은, const 키워드는 const 키워드 바로 다음에 오는것을 상수화 시킨다.
1. 변수의 상수화
const int A = 10;
int 형의 A 라는 이름을 가진 변수에 10을 넣고, 이를 상수화 시켜 사용하겠다는 의미이다.
이렇게 사용 시, A는 10이라는 값으로 고정되어 버리고, 어떤 방식으로든 수정이 불가능해진다. (상수 값이 되었으니..)
근데 이런 경우에, 만일 같은 이름 같은 타입의 변수를 다시 상수가 아닌 변수로 쓰고 싶다고 하면...
그냥 새로 선언해주면 끝이다.
이따구로 쓸 일이 있냐만은...
+ 특이 케이스 :
만일 const 멤버 상수에 레퍼런스를 붙인다고 하면, 레퍼런스 변수 또한 const로 선언해주어야 한다.
이유는 레퍼런스 접근을 통한 데이터 수정 방지.
애초에 굳이 const 선언해둔걸 억지로 애써서 수정할 필요가...?
하지말라면 하지말자.
2. 함수의 상수화 A
const int foo ();
함수의 리턴 타입에 상수 키워드가 붙는 경우이다.
이 경우는 사실 하나하나 따져보면 이해하기 쉬운게, "리턴 타입" 에 "상수 키워드", 즉 "리턴 값이 상수화" 된다는 의미와 동일하다.
즉, 함수가 실행되고 나온 결과값이 상수값이 되어 수정이 불가능한 값으로 얻어진다는 의미다.
어디다 써멱냐 싶지만, 생각보다 자주 보인다. 특히 문자열쪽이라던가.
간단히 이런식으로.
그럼 대입은 어떻게 하느냐?
그냥 쓰면 된다.
아무 문제 없음.
단지 가지고 있는 값이 현재 상수화 되어 보호되어 있다는것이지, 값을 누군가 대입받은 이후에는 그걸 어떻게 쓰던지 까지는 통제하지 않는다.
그냥 리턴값이 상수라는것만 기억하면 딱히 겁 먹을 필요 없음.
3. 함수의 상수화 B ; Const 멤버 함수
int foo() const;
이 케이스는 좀 특이 케이스인데, 함수 정의부가 상수화되어버린다.
무슨 얘기나면, 함수 내부에서는 값 변경이 불가능해진다 라는 의미이다.
더 정확히는, 함수 내부에서는 '지역변수를 제외한 모든 값에 대해 상수성을 보장한다' 라는 의미에 더 가까운데, 예를들어 함수 내에 값을 임시로 저장하기 위해 사용하는 temp 변수 등과 같은 케이스를 제외한 모든 경우에, 외부에서 진입된 값을 변할 수 없다는 의미이다.
이런 형태를 쓰는 케이스는 다양한 경우가 있는데, 가장 주의해야하는 케이스가 바로 포인터/레퍼런스 타입을 인자로 받는 경우이다.
값을 복사하지 않고 원본을 사용하기 위해 가져 왔는데, 이를 시스템상에서 보장을 하기 위해 내부를 상수화 시켜버리는 것이다.
정리하면
1) Const 멤버 함수를 호출할 경우 멤버들의 값 변경을 허용하지 않음.
2) 하지만, Const 멤버 함수의 지역 변수는 값 변경이 가능함.
3) Const 멤버 함수를 일반 멤버 함수에서 호출하는것은 문제가 없으나 역은 불가능함. (상수성 파괴 위험)
* 여기서 3번은 테스트가 좀 필요해 보인다. 실제로 저런 케이스를 접해본적이 없고 테스트를 어떻게 해봐야할지 감이 잘 안잡히기도 하고...
4. 객체의 상수화
여러가지 케이스가 있는데 여기선 1번과 유사한 경우로 설명한다.
리턴값이 객체거나, 혹은 객체를 멤버로 가지는 클래스 / 자료구조에 대한 경우, 혹은 객체를 보호하고 싶은 경우에 객체 앞에 const를 붙여서 값을 리턴시킨다.
당연하겠지만 값을 사용하는것엔 문제가 없으나... 값 자체를 수정하려는 경우 (ex : 리턴 된 값이 객체인 경우)에는 수정이 불가능함에 유의.
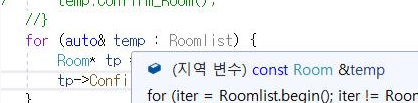
* Roomlist는 STL::Set 자료구조를 이용한 컨테이너 입니다.
위의 경우는 실제로 겪은 케이스인데, map / set 등과 같이 자동 정렬이 되는 자료구조 등을 사용할 경우, 구조상으로 정렬 상태를 외부에서 깨트리지 않게 하기 위해 내부 자료를 const 형으로 리턴해서 돌려준다.
즉, 리턴된 객체 전체가 const로 이루어져서 레퍼런스 접근임에도 불구하고 데이터 읽기만 가능하고 쓰기/수정이 전혀 불가능해지는 문제 아닌 문제가 발생한다.
5. const_cast
왠만하면 쓰지말자
객체/상수화 변수의 상수성을 깨트리는 역할을 한다.
4번의 경우와 유사하게, 내부 규칙을 깨트리진 않으나 값을 수정하려고 할때 const로 리턴받아질때 (문자열을 받는다거나 등) 상수성을 깨트리고 값을 사용하게 해주는 C++ 캐스트인데...
모 회사 면접 준비중에 예전에 당했던 문제가 생각나서 정리하려다, 문득 제대로 조사해본적이 없는거같아 기록용으로 작성한다.
사실, 검색해보다가 내가 시원하게 이해할만한 자료가 없었던것도 있고...
C에서 Char 형 배열 / 포인터로 겨우겨우 만들던 String에서 벗어나, 관리 함수등을 추가한 C++ String Class로 되면서, '어느정도는' 타 언어의 String 사용법과 비슷하게 이루어지기 시작했다. 물론, 문자열 다루는거는 Java 보다는 불편하긴한데, 이전 면접에서 '왜 불편한가요?' 라는 질문에 좀 어영부영 대답한 감이 없잖아 있는것같다.
따라서 포인터 개념이 살아있는 OOP인 C++과, 전부 GC로 관리되는 Java와 비교를 해보고자 한다.
1. C++ String의 경우 (wstring은 포함시키지 않음)
기본적으로 C++ String은 'Basic String' 이라는 자체 클래스를 내부에 구현한 상태로 되어있으며, Basic String의 생성자는 크게 'const Char *' 를 input으로 받는 경우, 자체 Allocator를 input으로 받는 경우(= 타 value_Type 배열포인터를 input으로 받는 경우), basic_string 참조값을 input으로 받는 경우로 나뉘어진다.
즉, 실제 구현에서는 '일단 모든 데이터형을 받을수 있도록' 구현이 되어있긴 하나, 문자열 자체를 받는경우는 여전히 Char 형 배열 포인터를 값으로 받는다... 고 설명할 수 있다.
그리고, String Class가 되면서, 각종 접근법 / 용량 체크 / 복사 / equal 등의 함수가 가능해졌다.
아래부터는 String str = "Hello World"; 라는 String을 선언해둔것으로 가정하고 시작한다.