원래 올해도 매달마다 회고 쓰고 그려려고 했는데 여의치가 않아서 (?) 2달치 몰아서 쓰게 되었습니다 ㅎ;
지금까지 있었던일
1. 취업/이직 -> 직장이야기
1) 새 회사 첫 출근
1월 6일자로 새로운 회사로 출근 시작했습니다.
곧 출시를 앞둔 게임 프로젝트를 진행중인 회사로, 포지션은 역시나 엔진 개발
다들 친절하고, 특히 바로 옆자리에 면접때 대학원생 보듯이 절 보던 분께서 앉아계시길래
'와 이거 진짜 옆에 두고 직접 조지겠단 뜻인가?' 싶었으나... 잘 도와주셔서 아직까지는 순탄하게 흘러가고 있습니다.. 만
2) 이거 맞습니까?
사실 출시 경험은 없어서 (라이브 1번, 출시 무산 1번이 전부임) 출시 직전은 무슨 일이 일어나나 했는데...
출근하고 일주일만에 바로 크런치 들어가는게 아닌가
'그... 맞아요?'
마치 앞으로의 험난한 여정을 알리는 서곡인듯, 출근 일주일차만에 야근 달리고는 정시퇴근은 꿈도 못하는 삶을 살고 있습니다...
아 뭐... 돈 많이주면 됐지 열심히 일할게요 젠장
3) "님 뒤졌음 ㅅㄱ"
어쩌다보니 프로젝트에서 좀 중요한 업무를 맡게 되었는데... 일단 이걸 이제 겨우 4년차 지나가는 뉴비(?)에게 시키는게 맞나 싶긴한데... 시키면 해야지 덕분에 여러 회사들이 얽혀있고, 참석자 평균 경력 15년이상되는 회의장에 끌려가질 않나.. 다사다난하게 살고 있습니다.
그러다 얼마전엔가 들은 이야기. 옆자리에 있는 선임분(흐뭇하게 보시던 그분맞음) 에게 물어볼게 있어서 물어봤더니 대답해주시고는 첨언을 해주시는데
앞으로 할일 많으니까 멘탈 털리지말고 어차피 다 할일이라 생각하세요
ㅖ?
저 망한거 같은데요
아니 이제 2달차인데 벌써 그런 소리 하시면 어떡합니가
여튼 덕분에 바들바들 사시나무마냥 살고 있습니다.
4) 일은 잘 하고 있음...
그래도 다행스러운건, 지금 하는 업무상태가 괜찮은지, 팀장님이나 선임분이나 업무 평가가 나쁘지 않다는 점.
"기대한것보다 잘 하고 있다" 라는 평가가 주류라, 아직은 잘하고 있구나... 하고 코드싸고 있습니다
그 이후로, 울릉도 여행 다녀오면서 머리를 식히고, 다시 준비한 결과 면접이 총 3개 가량이 잡혔고...
놀랍게도 "일단 1차는 전부 붙긴 했다"
근데, 결론만 말하면 역시나 아직도 취업을 못했다........
그 이유가 뭔고 하니...
2) 억까와 억까와 억까의 연속
우선... 9/10월 회고에 적었던 회사를 포함해서 총 3개였고,
한곳은 2차 탈락, 메타버스쪽은 최종합을 했으나 내가 거절, 그리고 대망의 NC는...
결론만 말하면 2차 탈락이긴 했다.
그런데, 아무리봐도 실력보다는 TO 이슈로 떨어진거 같다는 느낌을 지울수가 없다...
보통은 이게 "형식적인 얘기"지만...
NC 구조조정이슈 및 분사이슈 등으로 인해 (믿을만한 소식통에 따르자면) TO가 일단 반토막 나는것부터 시작했다고 하고, 사실상 "그나마 이미 알던 사람", 혹은 "진짜 걸러걸러서 단 한명" 정도만 뽑혔을거란 추측이 나왔다.
내가 면접을 완벽하게 잘 본건 아니고, 조금 하자가 있긴 했지만... 다른 지인들 의견도 그렇고, 내 의견도 그렇고...
내가 면접을 완벽하게 잘 봤어도 붙었을까?
라는 생각을 지울수가 없더라...
여튼, 덕분에 아직도 백수상태다.
3) 그래서 이제 뭐함?
실업급여도 끝난지 한달차, 이직도 안돼, 알바도 안구해져...
심지어 7월~8월 지나서는 면접 불러주는 빈도도 확 줄어버려서 거의 2개월째 추가 서류합격이 한번도 안 나고 있는 상태다.
...솔직히 착잡한데, 포기해야하나 싶다가도 대기업 2차까지도 가보고, 면접이 잡히기만 하면 1차는 이제 뚫리니까... 아직 할만하지 않을까...? 싶은 생각도 들기도 한다.
마음이 완전히 꺾이기 전에 이직 성공했으면 좋겠지만... 요즘 업계가 너무 안좋다보니 걱정이 이만저만이 아닌 상태다.
죽겠어요
4) 그 외 잡소리
NC 2차때 이런 소리 들었었다.
이력서에 하프라이프2 영상을 제출했는데, 면접관이 링크를 타고 프로필까지 봤었나보다.
그래서 면접 들어가자마자 들어간 소리가
"유튜버세요?"
진짜 상상치도 못한 질문에 한 3초 스턴 걸렸던거 같다.
2. 사람만나기
1) 이력서 검토 모임
트친(?) 중에 한분이 이력서 검토 행사를 열어주셨는데, 백수기도 하고 할거 없어서 그래도 이젠 서류도 종종 뚫리니까 도움좀 드릴겸 갔다왔었다.
생각보다 많은 참여자가 있었고, 나는 게임/보안쪽 검토담당으로 앉아서 열심히 검토를 빙자한 훈수를 두고 왔다...
그러면서 겸사겸사 내 이력서 + 경력기술서도 검토를 받았는데...
관련 코멘트 요약받은건 다음과 같았다.
경력기술서가 어필할 게 더 많은데, 자기소개서는 실제로 거의 다 안 읽음
면접관들의 시선은 기술이 먼저다.
자신이 있는 강점들이나, 기술적인 부분들을 맞춰서 어필하는 게 좋다.
면접관들이 아는 회사가 나올 수 있기 때문에 좋은 이야기들이 나올수 있게끔 해야한다.
부풀리지는 않되, 강점을 내세우고, 질문을 어떻게 준비할지 타이트하게 해야한다.
관심있는 포인트에 대해 어느 정도 깊이를 가지고 있는지, 관련 질문을 유도해야한다.
그러면서, 잘 쓴 편이라는 얘기를 듣긴 했다.
2) 튜사 회고모임
이제는 거의 한달마다 정기모임이 된 튜사 회고모임.
이번에도 다녀왔는데, 역시나 주변 얘기 듣고 온거 말고는 큰 기억이 나지는 않는다...
3. 운동/다이어트
1) 삭센다 1달 후기
삭센다를 처방받고 한달정도 맞아봤다.
우선 결론만 얘기하면 "효과는 있었다" / "요요도 심하다"
나 같은 경우에는 1회 용량을 1.8 (0.6ml~3.0ml 사이에서 0.6단위로 선택가능) 정도로 잡는게 가장 적절하다 느꼈는데, 이렇게 2주정도 맞으니까
1. 1회에 먹는 양이 줄어듬 (약 1/3이 줄어들었다)
2. 식사 간격이 늘어남
3. 저녁 먹고 특별한 활동을 하지 않으면 다음날까지 의식적으로 버티지 않더라도 버텨짐
4. 당 수치 저하 (애초에 삭센다 / 위고비 둘다 당뇨치료제 일종으로 나온거니까...)
의 효과를 봤었다.
하지만 자금 이슈로 권장 접종기간인 12주를 채우지 못하고, 현재는 그만둔지 약 2주차인데 취업 스트레스 이슈도 엮어서 그런가, 식사량이 다시 원상복귀 되버렸다.
씁....................
2) 그래서 살 뺐나요?
면접 준비 + 취업 스트레스 + 몸살 기타등등 이슈로 결국엔 변명이지만 운동을 별로 못가서 그런가 여전히 유지중이다.
나머지는 그냥 AbilitySystem Plugin을 추가하면 그만인데, GameplayCue는 선행작업이 좀 필요했다.
해당 내용을 검색을 해봐도, AI에게 물어봐도 시원하게 답을 주지 않았기에 직접 찾아보고 구현한 방법을 공유하고자 한다.
그래서 문제가 무엇인가
일단, 문제가 무엇인지부터 알아보자.
GameplayCue를 호출하기 위해서는 AbilitySystem이 추가될때 같이 추가되는 GameplayCueManager (이하 GCM이라 부름) 에 사용하고자 하는 GameplayCue들을 등록해주어야 한다.
이를 위해서는, AbilitySystemGlobal에 있는 GCM의 AddGameplayCueNotifyPath 라는 함수를 호출[1] 해주어야 하는데...
[1] (정확히는, 해당 함수를 호출해서, 경로에 있는 GameplayCue를 등록하게 해야한다)
...여기서 해당 함수를 호출하는 부분이 보이는가?
나는 아무리 눈을 씻고 찾아봐도 안보이더라
해서, 진짜 없나? 해서 뒤적대보니까 없는게 맞았다.
AbilitySystem 관련 샘플인 Lyra를 따라가자면, 해당 함수를 호출하는 Feature를 GameFeatureAction 항목에 추가하고, 경로를 지정해서 호출하게 해주어야 한다.
예시 확인
그럼 Lyra 프로젝트를 뜯어보는것으로 시작하자.
지금 진행중인 프로젝트의 버전과 동일한 엔진 버전을 가진 Lyra 프로젝트를 열고, 실행을 해보았다.
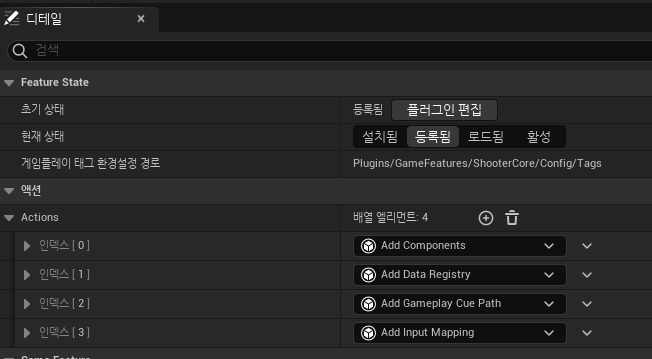
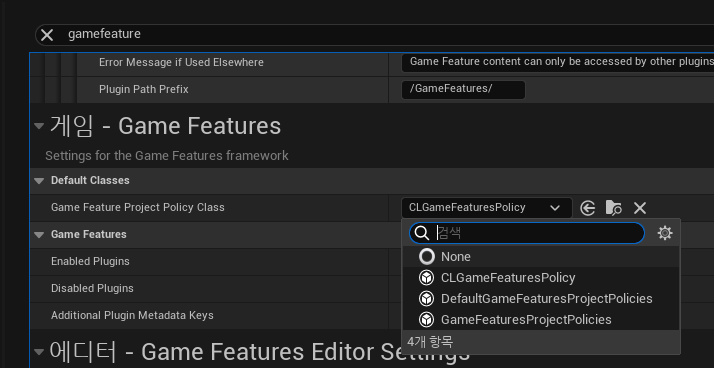
Lyra 프로젝트에 보면, 모든 게임피쳐 플러그인마다 해당 파일이 존재한다.
이 친구가 오늘의 핵심 되시겠다.
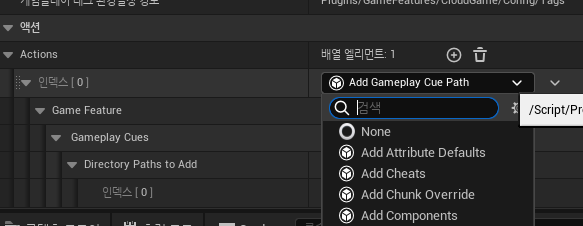
해당 파일을 열면, "액션" 탭에 여러 기능들이 포함되어있다.
여기서 이번에 추가할건 Add Gameplay Cue Path 라는 기능.
당연하게도 AbilitySystem만 세팅한 경우에는 저 항목이 존재하질 않는다.
해당 GameFeatureAction이 뭘 하는지, 어떻게 작동시키는지 살펴보자.
우선, 해당 기능은 2개의 클래스로 나뉜다.
1. GameFeatureAction으로 등록되는 클래스
2. GameFeatureAction에 의해 실제로 작동되는 클래스
왜 2개인지 까지는 이해를 못하겠는데, 일단 두개라고 하니까 둘다 구현해줘야한다.
"그냥 하나로 합치면 안되나요?"
라는 의문이 들 수 있는데, 시도해봤는데 안되더라.
문제점
이유는 다음과 같다.
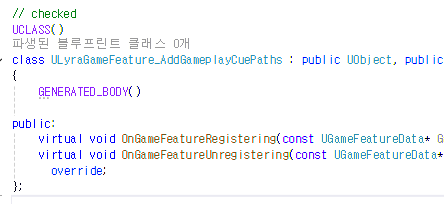
우선, Lyra 프로젝트에서 ULyraGameFeature_AddGameplayCuePaths 라는 클래스를 보자.
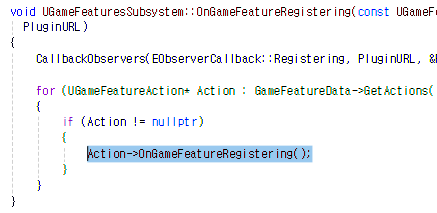
여기서 중요한건 "OnGameFeatureRegistering" 라는 함수.
해당 함수가 GameFeatureSubsystem 에 의해 호출되어야 해당 GameFeatureAction이 작동하는 구조인데... 호출되어야 하는 함수의 파라미터가 예상되는 파라미터와 전혀 다르다.
위의 잘린 이미지만 보면 알 수 있듯이, 파라미터가 좀 긴데
누구세요?
서브시스템 코드를 보면, 저 길다란 파라미터를 가진 함수를 호출하는 함수 호출부가 존재하지 않는다.
그 말은 즉슨, 다른 방식으로 호출해야한다는 뜻.
해당 방식은 먼곳 갈 필요없이, 바로 위에 있는 CallbackObservers에서 호출된다.
Observer에 등록해두면, 해당 파라미터타입을 가진 클래스가 호출된다는것.
...뭔가 이상하지 않은가?
1. OnGameFeatureRegistering 라는 함수가 호출되어야 한다는건 알겠고
2. OnGameFeatureRegistering가 Observer에 의해 호출되어야 한다는건 알겠는데
3. 그럼 GameFeatureAction은 어떻게 만드는데?
놀랍게도 GameFeatureAction 클래스는 따로 만들어줘야한다.
구현하기
이제 차근차근 구현해보도록 하자.
1. 타 GameFeatureAction이나, Lyra 프로젝트를 참고해서 "AddGameplayCuePath"를 수행할 수 있는 GameFeatureAction 클래스를 생성한다.
UCLASS(MinimalAPI, meta = (DisplayName = "Add Gameplay Cue Path"))
class UGameFeatureAction_AddGameplayCuePath final : public UGameFeatureAction
{
GENERATED_BODY()
public:
UGameFeatureAction_AddGameplayCuePath();
//~UObject interface
#if WITH_EDITOR
virtual EDataValidationResult IsDataValid(class FDataValidationContext& Context) const override;
#endif
//~End of UObject interface
const TArray<FDirectoryPath>& GetDirectoryPathsToAdd() const { return DirectoryPathsToAdd; }
private:
/** List of paths to register to the gameplay cue manager. These are relative tot he game content directory */
UPROPERTY(EditAnywhere, Category = "Game Feature | Gameplay Cues", meta = (RelativeToGameContentDir, LongPackageName))
TArray<FDirectoryPath> DirectoryPathsToAdd;
};
해당 클래스는 "껍데기" 에 해당하는 클래스라서, 구현도 크게 고민 안해도 된다.
그냥 참고한 프로젝트들이나 코드를 보면서 작성하면 되는데, 추가로 설명해주자면..
#include "GameFeatureAction_AddGameplayCuePath.h"
#if WITH_EDITOR
#include "Misc/DataValidation.h"
#endif
#include UE_INLINE_GENERATED_CPP_BY_NAME(GameFeatureAction_AddGameplayCuePath)
#define LOCTEXT_NAMESPACE "GameFeatures"
UGameFeatureAction_AddGameplayCuePath::UGameFeatureAction_AddGameplayCuePath()
{
// Add a default path that is commonly used
DirectoryPathsToAdd.Add(FDirectoryPath{ TEXT("/GameplayCues") });
}
#if WITH_EDITOR
EDataValidationResult UGameFeatureAction_AddGameplayCuePath::IsDataValid(FDataValidationContext& Context) const
{
EDataValidationResult Result = Super::IsDataValid(Context);
for (const FDirectoryPath& Directory : DirectoryPathsToAdd)
{
if (Directory.Path.IsEmpty())
{
const FText InvalidCuePathError = FText::Format(LOCTEXT("InvalidCuePathError", "'{0}' is not a valid path!"), FText::FromString(Directory.Path));
Context.AddError(InvalidCuePathError);
Result = CombineDataValidationResults(Result, EDataValidationResult::Invalid);
}
}
return CombineDataValidationResults(Result, EDataValidationResult::Valid);
}
#endif // WITH_EDITOR
#undef LOCTEXT_NAMESPACE
그냥 이게 끝이다.
별거 없다. 어차피 DataValid는 Editor 전용 코드기 때문에 가려질것이고, 기본 Path만 추가해주면 끝.
문제는 지금부터다.
2. 실제로 기능하는 GameFeatureAction을 만들어준다.
여기서 참고해야하는 클래스는 Lyra 프로젝트의 ULyraGameFeature_AddGameplayCuePaths 라는 클래스다.
근데 해당 클래스를 보면, UObject와 IGameFeatureStateChangeObserver 라는 인터페이스를 상속받는 형태의 클래스로 되어있다.