간단히, '상수화 키워드' 로 알려져 있는 이 키워드는, 말 그대로 해당 키워드가 붙는 모든것을 상수화 (고정값 화) 시켜버린다.
여기서 알아두어야 할 것이, 모든 것이라는 점인데, 단순히 변수는 물론이고, 함수 삽입값(파라미터), 함수 리턴값, 심지어는 클래스/객체에도 사용이 가능하다.
근데 이게 어디 붙여도 다 상수화.... 되는건 맞는거 같은데, 좀 헷깔리는 감이 없잖아 있어서 정리를 좀 해보고자 한다.
일단 알아두어야 할 점은, const 키워드는 const 키워드 바로 다음에 오는것을 상수화 시킨다.
1. 변수의 상수화
const int A = 10;
int 형의 A 라는 이름을 가진 변수에 10을 넣고, 이를 상수화 시켜 사용하겠다는 의미이다.
이렇게 사용 시, A는 10이라는 값으로 고정되어 버리고, 어떤 방식으로든 수정이 불가능해진다. (상수 값이 되었으니..)
근데 이런 경우에, 만일 같은 이름 같은 타입의 변수를 다시 상수가 아닌 변수로 쓰고 싶다고 하면...
그냥 새로 선언해주면 끝이다.
이따구로 쓸 일이 있냐만은...
+ 특이 케이스 :
만일 const 멤버 상수에 레퍼런스를 붙인다고 하면, 레퍼런스 변수 또한 const로 선언해주어야 한다.
이유는 레퍼런스 접근을 통한 데이터 수정 방지.
애초에 굳이 const 선언해둔걸 억지로 애써서 수정할 필요가...?
하지말라면 하지말자.
2. 함수의 상수화 A
const int foo ();
함수의 리턴 타입에 상수 키워드가 붙는 경우이다.
이 경우는 사실 하나하나 따져보면 이해하기 쉬운게, "리턴 타입" 에 "상수 키워드", 즉 "리턴 값이 상수화" 된다는 의미와 동일하다.
즉, 함수가 실행되고 나온 결과값이 상수값이 되어 수정이 불가능한 값으로 얻어진다는 의미다.
어디다 써멱냐 싶지만, 생각보다 자주 보인다. 특히 문자열쪽이라던가.
간단히 이런식으로.
그럼 대입은 어떻게 하느냐?
그냥 쓰면 된다.
아무 문제 없음.
단지 가지고 있는 값이 현재 상수화 되어 보호되어 있다는것이지, 값을 누군가 대입받은 이후에는 그걸 어떻게 쓰던지 까지는 통제하지 않는다.
그냥 리턴값이 상수라는것만 기억하면 딱히 겁 먹을 필요 없음.
3. 함수의 상수화 B ; Const 멤버 함수
int foo() const;
이 케이스는 좀 특이 케이스인데, 함수 정의부가 상수화되어버린다.
무슨 얘기나면, 함수 내부에서는 값 변경이 불가능해진다 라는 의미이다.
더 정확히는, 함수 내부에서는 '지역변수를 제외한 모든 값에 대해 상수성을 보장한다' 라는 의미에 더 가까운데, 예를들어 함수 내에 값을 임시로 저장하기 위해 사용하는 temp 변수 등과 같은 케이스를 제외한 모든 경우에, 외부에서 진입된 값을 변할 수 없다는 의미이다.
이런 형태를 쓰는 케이스는 다양한 경우가 있는데, 가장 주의해야하는 케이스가 바로 포인터/레퍼런스 타입을 인자로 받는 경우이다.
값을 복사하지 않고 원본을 사용하기 위해 가져 왔는데, 이를 시스템상에서 보장을 하기 위해 내부를 상수화 시켜버리는 것이다.
정리하면
1) Const 멤버 함수를 호출할 경우 멤버들의 값 변경을 허용하지 않음.
2) 하지만, Const 멤버 함수의 지역 변수는 값 변경이 가능함.
3) Const 멤버 함수를 일반 멤버 함수에서 호출하는것은 문제가 없으나 역은 불가능함. (상수성 파괴 위험)
* 여기서 3번은 테스트가 좀 필요해 보인다. 실제로 저런 케이스를 접해본적이 없고 테스트를 어떻게 해봐야할지 감이 잘 안잡히기도 하고...
4. 객체의 상수화
여러가지 케이스가 있는데 여기선 1번과 유사한 경우로 설명한다.
리턴값이 객체거나, 혹은 객체를 멤버로 가지는 클래스 / 자료구조에 대한 경우, 혹은 객체를 보호하고 싶은 경우에 객체 앞에 const를 붙여서 값을 리턴시킨다.
당연하겠지만 값을 사용하는것엔 문제가 없으나... 값 자체를 수정하려는 경우 (ex : 리턴 된 값이 객체인 경우)에는 수정이 불가능함에 유의.
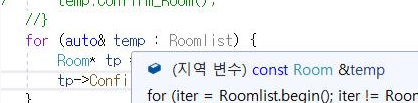
* Roomlist는 STL::Set 자료구조를 이용한 컨테이너 입니다.
위의 경우는 실제로 겪은 케이스인데, map / set 등과 같이 자동 정렬이 되는 자료구조 등을 사용할 경우, 구조상으로 정렬 상태를 외부에서 깨트리지 않게 하기 위해 내부 자료를 const 형으로 리턴해서 돌려준다.
즉, 리턴된 객체 전체가 const로 이루어져서 레퍼런스 접근임에도 불구하고 데이터 읽기만 가능하고 쓰기/수정이 전혀 불가능해지는 문제 아닌 문제가 발생한다.
5. const_cast
왠만하면 쓰지말자
객체/상수화 변수의 상수성을 깨트리는 역할을 한다.
4번의 경우와 유사하게, 내부 규칙을 깨트리진 않으나 값을 수정하려고 할때 const로 리턴받아질때 (문자열을 받는다거나 등) 상수성을 깨트리고 값을 사용하게 해주는 C++ 캐스트인데...
(전부 다 를 다루는것이 아닌, "아마 회사 입사 테스트에서 봤던거 같은" 애들 위주로 정리합니다.)
1. 자료구조
1) 분류
(1) 선형 구조 : 선형 리스트(=배열), 연결리스트, 스택, 큐, 덱
(2) 비선형 구조 : 트리 (및 트리를 기반으로 한 자료구조), 그래프
2) 요약
(1) 연결리스트 : 각 노드의 포인터 부분을 이용하여 서로 연결시킨 자료구조.
(2) 스택 : 리스트의 한쪽 끝에서만 Input/Output이 가능. "LIFO" 구조의 자료형
(3) 큐 : 선형 리스트의 한쪽에선 Input, 다른 쪽에선 Output만 진행. "FIFO"구조의 자료형
(4) 덱 (Deque) : Input, Output이 양쪽에서 발생가능. 단 입/출력이 모두 양쪽에서 발생하진 않음.
(5) 트리 : Node (정점)과 가지 (Branch)를 이용하여 사이클을 이루지 않게 구현된 그래프.
Root Node에서 시작.
트리의 깊이 (Depth) : 트리 노드의 최대 길이.
트리의 차수 (Degree) : 각 노드에서 뻗어나온 가지의 수
단말 노드 (Terminal Node, Leaf Node) : 자식이 하나도 없는 (= Degree Zero) 노드
3) 이진 트리 운행
(1) Pre order (전위) : Root -> Left -> Right 순으로 진입.
(2) In Order (중위) : Left -> Root -> Right 순으로 진입.
(3) Post Order (후위) : Left -> Right -> Root 순으로 진입.
2. 정렬 / 탐색 알고리즘 기본
1) 기본
(1) 오름차순 : 다음 차수로 갈수록 값이 올라감. 1,2,3,4,5...
(2) 내림차순 : 다음 차수로 갈수록 값이 내려감. 5,4,3,2,1...
2) 종류 1 (오름 차순 기준)
(1) 삽입 정렬 : i값과 i+1 값을 비교 후, i > i+1 일 시 i+1을 i 이전에 삽입. 앞 부터 정렬됨
(2) 버블 정렬 : i값과 i+1 값을 비교 후, i > i+1 일 시 서로 맞바꿈. 뒤 부터 정렬됨
(3) 선택 정렬 : i값과 i+a 값을 비교, i > i+a 일 시 위치를 바꿔줌. i 값을 점진적으로 증가시킴 (i+a<=N)
3) 종류 2
(1) 이진 탐색 : 전체 리스트를 2개의 서브 리스트로 분리하여 탐색함.
찾고자 하는 값을 값의 중간값과 비교하며 검색.
중간 레코드 값은 ((첫번째 레코드 번호 + 마지막 레코드 번호)/2) 로 계산
(2) 해싱 : 해시 함수를 이용하여 리스트에 대한 Hash Table의 위치를 계산후 값을 저장하거나 검색함.
3. 파일 처리 / 파일 구조
1) 순차 파일 처리 : 입력되는 데이터를 논리적인 순서에 따라 물리적 연속공간에 저장.
기록 속도는 빠르나 삽입 / 수정 / 삭제, 검색은 매우 느림.
2) 색인 순차 파일 : 순차 & 랜덤 처리가 가능하도록 레코드를 정렬시켜 기록, 키 항목만을 모은 색인을 구성.
4. 논리 게이트 (시나공 2017 요약본 참조)
자세한것은 진리표 참조
5. 기초 표현
1) 2진법 / 8진법 / 16진법
(1) 2진법 : 0,1로만 값을 표현. 2의 배수 만큼 올라감
(2) 8진법 : 0~7까지의 값으로 표현, 2진법으로 변환 시 값 3개를 묶음 (000~111)
(3) 16진법 : 0~9,A~F (10~15) 까지의 16개 값으로 표현, 2진법으로 변환 시 값 4개를 묶음 (0000~1111)
2) 보수 (2진법 한정)
(1) 1의 보수 : 0과 1의 값을 뒤집음.
(2) 2의 보수 : 0과 1의 값을 뒤집고 1의 자리에 +1
3) 부동 소수점 표현 1 (float)
0bit : 부호
1~7 bit : 지수부
8~31 bit : 가수부
4) 자료 표현 코드
(1) BCD 코드 : 10진수 1자리를 2진수 4bit로 표현
(2) Excess-3 (3초과 코드) : BCD +3
(3) Gray 코드 : BCD 인접 코드를 XOR 연산을 이용하여 만듬
(4) 패리티 검사 코드 : 데이터 비트에 1bit의 패리티 비트 추가 (Odd : 1 Bit의 수가 홀수 / Even : 1Bit의 수가 짝수)
6. 컴퓨터 구조
1) CPU
(1) 제어 장치 : 장치들의 동작을 지시 / 제어. 주기억 장치에서 읽어들인 명령어를 해독, 제어 신호를 보냄
(2) 연산 장치 : 산술, 논리, 관계, Shift 연산 등을 수행. (ALU 등)
(3) 레지스터 : CPU 내부의 임시 기억 장소
2) BUS
: CPU, 메모리, I/O 장치 등과 상호 필요한 정보를 교환하기 위한 공동 전송선.
(CPU 연산 처리 체제에도 영향을 많이 받음 (32bit / 64bit 등))
3) CPU 상태
Fetch, Indirect, Execute, Interrupt의 4가지.
(1) Fecth : 명령어를 주기억 장치에서 CPU의 명령 레지스터로 가져와 해독
(2) Indirect : Fetch 단계에서 해석된 명령의 주소부가 간접 주소인 경우. 명령의 유효주소를 계산.
(3) Execute : 명령어를 수행하는 단계
(4) Interrupt : 문제 (Interrupt)가 발생할 시 복귀 주소 (Program Counter ; PC)를 저장시키고, 제어 순서를 인터럽트 처리의 첫번째 명령으로 이동.
인터럽트 이후 정상적인 과정에서는 Fatch로 복귀함.
4) 하드디스크
(2) Access Time
= Seek Time + Latency Time + Transmission Time
(Seek Time = 탐색 시간 : Head 이동 시간) / (Latency Time = Search Time = 회전 지연 시간, 특정 섹터 데이터가 Head까지 가는 시간) / (TransMission Time = 전송 시간 : Head Access Data 와 주기억 장치간의 데이터가 전달되는 시간)
5) Cache Memory
(L1, L2 캐시라고 불리던 그거)
CPU와 메모리 간의 속도차이를 줄이기 위해 사용하는 Buffer Memory.
Cache Hit Percent (캐시 적중률) = 적중 횟수 / 총 접근 횟수
6) 가상 메모리
(1) 이론 : MMU (Memory Management Unit)을 이용, CPU의 연산 비트수에 매치되는 메모리 사이즈를 실제 존재하는것처럼 인지시켜 컨트롤 시키는 공간.
각 프로세스는 자신만의 가상 주소 공간을 가지고 있으며, 프로그램에서 메모리 주소에 접근시 'logical memory' 주소에 접근하도록 유도한다.
실제로는 모든 프로세스가 자신만의 가상 주소 공간을 가지고 있어, 물리적인 메모리 주소로만 접근시 충돌이 일어날 수 있기에 프로세스의 logical memory 와 physcial memory를 분리시키기 위해 만들어진 구조이다.
(2) 'Page' : 가상 메모리를 사용하는 최소 크기 단위.
(3) Demending Page : 실제로 필요한 Page를 물리 메모리로 로드하는 단계.
(4) Page Fault : 필요한 Page가 물리 메모리에 존재하지 않는 경우. 이 경우 원하는 Page를 물리 메모리로 로드하는 과정이 일어난다.
7) 기억장치 배치 전략
(1) First Fit : 프로그램 / 데이터가 들어갈 수 있는 첫번째 공간에 삽입
(2) Best Fit : 프로그램 / 데이터가 들어갈 수 있는 가장 작은 공간에 삽입
(3) Worst Fit : 프로그램 / 데이터가 들어갈 수 있는 가장 큰 공간에 삽입
8) 단편화
(1) 내부 단편화 : 내부 분할 영역이 할당될 프로그램의 크기보다 큼으로써, 할당 후 사용되지 않고 남은 공간.
(2) 외부 단편화 : 내부 분할 영역이 할당될 프로그램의 크기보다 작음으로써 할당될 수 없이 남아있는 공간.
7. 운영체제
2) 프로세스 : 프로세서 (CPU 등)에 의해 처리되는 사용자 프로그램이나 시스템 프로그램을 의미.
3) 스레드 : 하나의 프로세스 내에서 작동하는 스케쥴링의 최소 단위. 서로 독립적인 다중 수행 가능.
(1) 사용자 수준 스레드 : 사용자측 라이브러리를 이용하여 스레드 운용.
(2) 커널 수준 스레드 : 운영체제 커널에서 스레드 운용.
4) 상호 배제 :
(1) 임계 구역 : 공유 데이터 및 자원. 특정 시점에는 단 한개의 프로세스만 자원을 차지할수 있도록 지정된 공유 자원.
(2) 상호 배제 (Mutual Exclusion) : 특정 프로세스가 공유 자원 사용시 타 프로세스가 사용할 수 없도록 제어.
(3) 세마포어 : 각 프로세스에 제어 신호를 전달, 순서대로 작업을 수행. 프로세스간 동기화 유지 및 상호 배제 보장.
(4) 교착 상태 (Deadlock) : 자원 무한정 대기 상태
교착 상태의 필요 충분 조건
- 1 : 상호 배제 : 한번에 한개의 프로세스만이 공유 자원 사용
- 2 : 점유/대기 (Hold & Wait) : 최소 하나의 자원을 점유중에 타 자원을 추가 점유하려고 대기중인 프로세스 존재
- 3 : 비선점 : 다른 프로세스에 할당된 자원은 끝날때까지 뺏을수 없음
- 4 : 환형 대기 (Circular Wait) : 프로세스대기가 원형으로 구성되어 자신에게 할당된 자원을 점유하며 앞/뒤의 프로세스 자원을 요구
교착상태 해결 기법
- 1 : 회피 기법 : 교착상태가 발생시 피해나감.
- 2 : 발견 기법 : 시스템에 교착상태가 발생했는지 점검.
- 3 : 회복 기법 : 교착상태 프로세스를 종료하거나 자원 선점하여 프로세스 혹은 자원 회복
8. 프로세서 스케줄링
(1) 정의 : 시스템의 여러 자원을 필요한 프로세스에게 할당하는 작업
(2) Context Switching (문맥 교환) : A 프로세스에서 B 프로세스로 CPU가 할당되는 과정에서 발생하는 일련의 작업.
현재 CPU가 할당된 프로세스의 상태 정보를 저장 -> 새로운 프로세스의 상태 정보 설정 -> CPU 할당
CPU Overhead의 주 요인중 하나
(3) 비 선점형 스케줄링 : 이미 할당된 CPU를 뺏어갈 수 없음, 할당받을시 완료시까지 CPU 사용
1) FCFS (=FIFO) : 도착한 순서에 따라 차례로 CPU를 할당함
2) SJF (Shortest Job First) : 실행시간이 가장 짧은 프로세스부터 CPU 할당
3) HRN (Hightest Response-ratio Next) : SJF 보완, 우선순위에 따른 CPU 할당
우선순위 계산 공식 = (프로세스 대기시간 + 서비스 시간)/서비스 시간
결과값이 높을수록 우선순위가 빨리 부여됨.
(4) 선점형 스케줄링 : 준비상태 큐의 프로세스 중에 우선순위가 가장 높은 프로세스에게 먼저 CPU를 할당.
1) SRT (Shortest Remaining Time) : SJF의 선점형, 가장 짧은 시간이 남은 프로세스부터 CPU 할당
2) RR (Round Robin) : 시분할 시스템을 위해 고완, FIFO를 선점형태로 변형.
FIFO 기반이나, '할당 시간' 만큼 CPU를 사용 후, 실행이 완료되지 않으면 다음 프로세스에게 CPU를 넘기고 준비상태 큐의 가장 뒤로 배치됨.
할당 시간이 클수록 FIFO와의 차이가 사라지고, 할당 시간이 작을수록 Context Switching과 Overhead 가 자주 일어남.
9. 네트워크
1) 경로 제어 (라우팅 기법)
(1) IGP - RIP : 최대 홉 수를 15로 제한. 특정 시간단위로 라우팅 정보 갱신
(2) IGP - OSPF : 홉 수에 제한이 없음. 라우팅 정보가 갱신될 때 변화정보만 모든 라우터에 알림
(3) EGP : 게이트웨이 간의 라우팅
(4) BGP : EGP의 단점 보완. 처음에는 RIP처럼 전체 경로 제어표 교환, 이후에는 OSPF처럼 변화정보만 교환.
2) 망 구조
(1) 성형 (Star) : 중앙 집중형
(2) 순환형(Ring) : 단말기들을 이웃하는것끼리 Point To Point 연결시킨 형태.
(3) 버스형(Bus) : 한개의 통신회선에 여러 단말기가 연결됨.
(4) 계층형(Tree) : 분산처리 구성 방식.
(5) 망형(Mesh) : 모든 지점의 컴퓨터와 단말기를 서로 연결.
필요 회선 수 = (n(n-1))/2
3) 인터넷 주소 체계
(1) IP Class :
Class A : 국가 / 대형 통신망 (2^24)
Class B : 중대형 통신망 (2^16)
Class C : 소규모 통신망 (2^8)
Class D : 멀티 캐스트용
Class E : 실험용 (예비)
(2) 서브넷 마스크 : 4바이트의 IP주소 중 네트워크 주소와 호스트 주소를 구분하기 위한 비트
(3) IPv6 : 16비트씩 8부분으로 구성됨
(4) 도메인 네임 : IP주소와 매치되는, 문자로 구성된 주소
(5) DNS : 도메인 네임과 IP 주소를 상호변환해주는 시스템/서버
4) OSI 참조 모델
(7) 응용 계층 : 사용자 (응용 프로그램)이 OSI 환경에 접근할 수 있도록 서비스 제공.
(6) 표현 계층 : 응용계층 <> 세션계층 간 데이터 변환. 코드 변환, 데이터 암호화, 구문검색, 문맥관리 등
(5) 세션 계층 : 송 수신측 관련선 유지, 대화 제어
(4) 전송 계층 : 종단 시스템간 데이터 전송을 가능하게 함, 전송 연결 설정, 데이터 전송, 흐름제어 등 <TCP/UDP>
(3) 네트워크 계층 : 개방 시스템간의 네트워크 연결관리, 데이터의 교환 및 중계, 경로설정, 트래픽 제어 등 <IP>
(2) 데이터 링크 계층 : 두개의 인접한 개방 시스템간의 신뢰성 있는 정보전송을 위함. 흐름제어, 오류제어 등 <LLC>
(1) 물리 계층 : 장치간 실제 접속관 절단 등에 필요한 기계적, 전기적, 기능적, 절차적 특성 <RS-232C>
5) TCP/IP 계층 모델
(4) 응용 계층
(3) 전송 계층
(2) 인터넷 (=네트워크) 계층
(1) 네트워크 엑세스 계층 : 실제 데이터 송/수신
6) 주요 프로토콜
(1) TCP : 전송계층, 신뢰성 있는 연결형 서비스 제공. FTP, SMTP (메일), HTTP 등
(2) UDP : 전송계층, 빠른 비연결형 서비스 제공, 동시에 여러 사용자에게 데이터 전달할 경우. 실시간 전송에 유리.
(3) IP : 네트워크 계층, 데이터그램을 기반으로 한 비연결형 서비스 제공. 패킷 분해/조립, 주소 지정, 경로 선택 등
(4) ICMP : IP와 조합, 통신중에 발생하는 오류 처리, 전송 경로 변경 등을 위한 제어메시지 관리
(5) ARP : IP주소에서 물리주소 (MAC Address) 로 변환
(6) RARP : 물리주소에서 IP주소로 변환
10. 보안
1) 암호화 기법
(1) 비밀키 시스템 : 동일한 키로 데이터 암호/복호화. 대칭 암호화 기법
(2) 공개키 시스템 : 서로 다른 키로 데이터 암호화 / 해독하는 비대칭 암호화 방식. 키의 분배 용이.
// Copyright 1998-2019 Epic Games, Inc. All Rights Reserved.
using UnrealBuildTool;
using System.Collections.Generic;
public class FindRandomMapTarget : TargetRules
{
public FindRandomMapTarget(TargetInfo Target) : base(Target)
{
Type = TargetType.Game;
DefaultBuildSettings = BuildSettingsVersion.V2;
ExtraModuleNames.Add("FindRandomMap");
ExtraModuleNames.Add("PMG"); //추가
}
}